

I have been working for the last handful of months to understand what performance means for a product, and how we can discover and fix the bottlenecks in the engineering to improve the quality of the product for consumers.
One thing that we all would agree on? — Performance is hard!
Performance is a heavy & verbose class of problem that requires both depth-wise and breadth-wise understanding of product and engineering to make significant improvements.
Though performance is rightfully perceived from consumer’s perspective but it has multiple layers of engineering — First Contentful Paint time, Bundle Size Download time, Memory Usage, API Latency, Server’s Processing Time etc.
All these hot spots if degraded can potentially convert into low NPS of your product, increased churn rate, rise in support tickets, and an overall low-quality & unusable product for consumers.
I am not an expert, and I don’t understand all these layers entirely. However, while working on the API performance I discovered a generic-behaviour worth discussing.
Outliers’ behaviour that we usually miss;
Looking at the broader trends of system’s vitals - Availability Score, SLOs, Response Times, we can point out the majority of the performance degradation issues’ existing in a system. The root cause itself might be too complicated and could require a deeper level of work.
Figuring out the significant patterns that affect critical user journeys in a product and solving for them should be the priority for any team. And this works amazingly well, but not always.
Interestingly, if you start exploring the outlier behaviour in your systems which usually gets masked by the overall (average) behaviour, you will see patterns that are off the charts. For example, the average response time of API might be blazing fast <100ms but for the tail users (1%) the response time might be as worse as 10s!
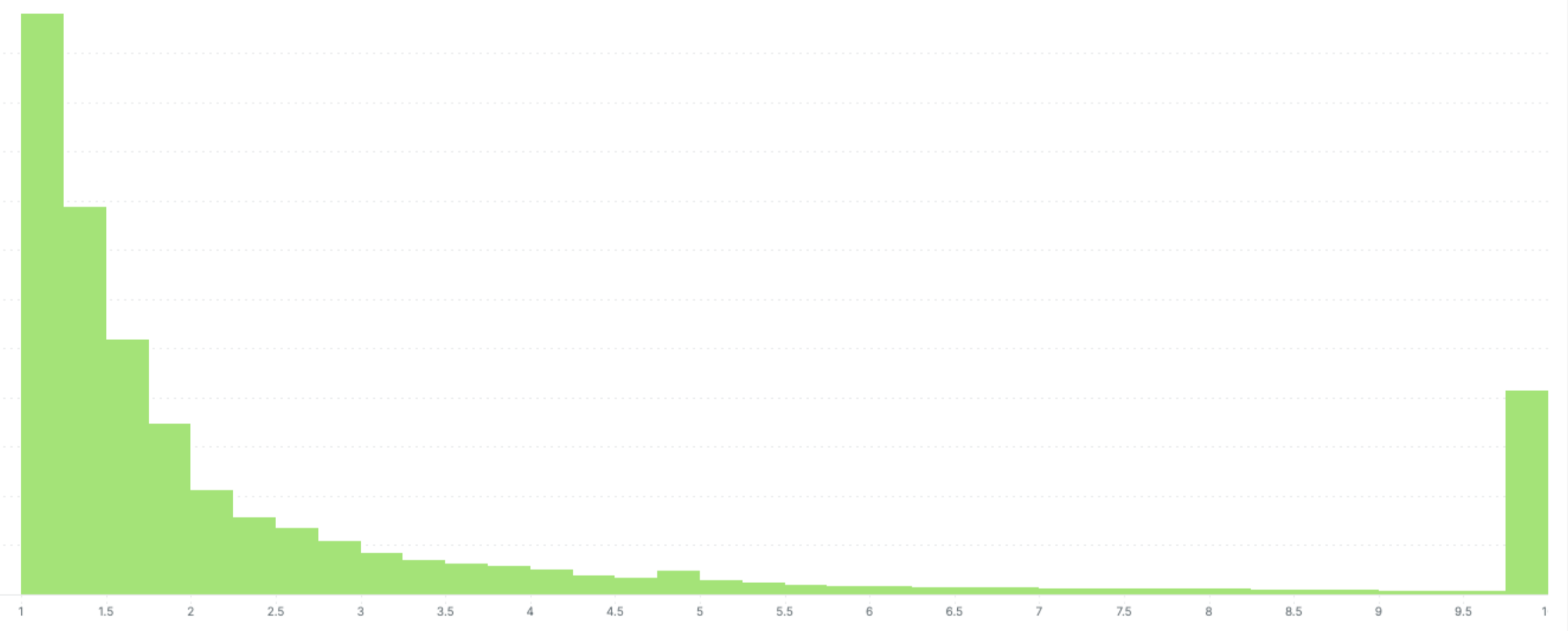
This outlier behaviour is universal and not just not limited to API Response time. However, not all outlier behaviour has to be solved. There are real-world factors that an organisation’s engineering team cannot control. A few of them are;
Users’ poor internet bandwidth (There is an extent to which you can solve this)
Users are running on the older versions of product and haven’t updated
Users might be using not-so-common OS platform version, and haven’t patched
In most cases, engineering teams are okay to not care about outliers’ behaviour either because of above practical reasons or it’s not worth the effort compared to other tasks.
This is what we miss; Not all outlier behaviour has to be solved, but all of them has to be explored because each of them is a potential path to performance degradation for all users. Quoting the same example of elevated API response times — A spike in high response time could exhaust the CPU resources for a short period of time that even auto-scaling / buffer might not help. All the other requests could either face elevated queue time or may get dropped altogether causing a bigger blast radius.
Patterns like these exist everywhere, hypothetically saying, let’s assume Google Docs works really well upto X users, and suddenly X + Y users starts collaborating and sends heavy amount of large network packets to servers for syncing (even for differential). This could potentially swamp the resource usage, and might affect other users whose requests are being served by the same server. I know there are multiple ways to solve this and Google Docs don’t even have this problem, so don’t kill me for a bad example.
Be cautious, and don’t ignore the outlier patterns.
See ya!
Beautifully presented and very well explained. The article is very to the point.